음성(Voice)은 진보된 휴먼인터페이스로 지능형 클라우드를 기반으로 한 서비스 및 엣지 디바이스 사용시 효과적인 입력 수단으로 최근 주목받고 있는 기술이다. 음성 (Voice)은 빠른 속도로 지능형 디바이스의 혁명을 이끄는 휴먼 인터페이스 입력신호가 되었지만 이를 인식하는 기능을 구현하기에는 가장 복잡한 기술 중 하나이다
CEVA가 신경망 네트워크를 기반으로 한 음성인식 기술 WhisPro를 14일 발표했다.
CEVA의 저전력 음성 및 오디오 신호처리 기술을 활용한 WhisPro는 상시 청취형 멀티-트리거 프레이즈 인식 기술(Always-listening Multi-trigger Phrase)이다. 새로운 스마트폰, 스마트 스피커, 블루투스 이어폰 및 기타 음성 지원 디바이스의 사용자가 아마존 알렉사, 구글 어시스턴트, 바이두 DuerOS 등의 클라우드 기반 음성 비서(Voice Assistant)와 상호 호환되어 동작할 수 있도록 지원한다.
또한, CEVA는 고객에게 자동차, 스마트홈, 엔터프라이즈 등을 포함한 다양한 유스케이스 및 엔드 마켓에 자신만의 음성 제어를 적용시킬 수 있는 트리거 프레이즈 커스터마이징 서비스(Trigger Phrase Customization Service, 작동 문구 맞춤화 서비스)를 제공한다. 지난주 라스베가스에서 열린 CES 2019에서 이 기능을 탑재한 WhisPro 를 선보였다.
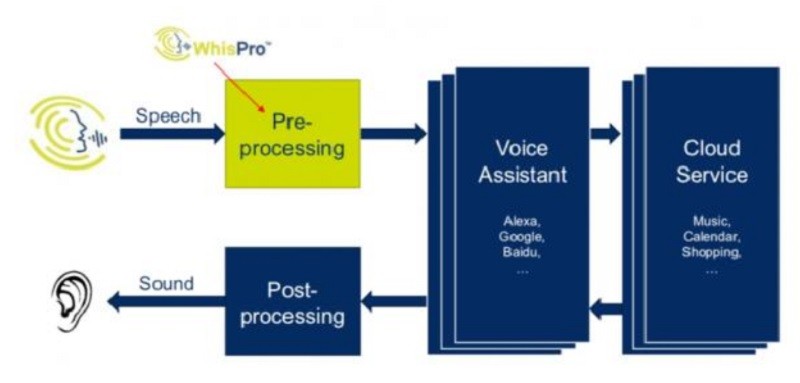
WhisPro는 CEVA의 ClearVox 프론트-엔드 음성 신호처리 소프트웨어 기술(Front-end Voice Processing Software)과 함께 작동하며, CEVA DSP를 기반으로 한 견고한 음성인식용 하드웨어 및 소프트웨어 솔루션을 제공한다. 이러한 음성신호 전처리 기술과 신경망 네트워크 알고리즘의 총체적 통합은 컴퓨팅 리소스 및 전력을 최소한으로 소모함과 동시에 95% 이상의 높은 인식률을 실현한다. 이 기술은 시끄러운 환경 속에서도 근거리 및 원거리 모두에서 선명한 복원력을 보여준다. 뿐만 아니라 클라우드 백업 없이 엣지 디바이스에서 바로 작동하므로 사용자 프라이버시가 보호되고, 지연이 최소화 된 즉각적인 응답을 제공한다.
음성 AI 기술을 기반으로 엣지 디바이스용으로 최적화된 WhisPro의 재귀 신경망 네트워크 기술은 다중 트리거 프레이즈를 동시에 인식할 수 있다. WhisPro SDKit은 시스템 상에서 WhisPro 기술을 통합하고 테스트하는 가이드라인과 툴을 고객에게 제공한다. 고객의 요청에 따라 키워드와 다중 언어에 대한 다중 발음을 지원하며 현재는 영어가 지원되며 향후 중국어도 지원할 예정이다.
WhisPro는 현재 CEVA-TeakLite-4, CEVA-X2 및 CEVA-BX DSP 고객을 대상으로 라이센싱이 가능하며, 주요 Tier-1음성인식 비서 기능 서비스와 연동된다.
CEVA의 에레즈 바니브(Erez Bar-Niv) CTO 는 "CEVA는 비용 효율성, 정확성, 소음 완화 모두를 실현하는 기술 지원을 목적으로 한다. WhisPro는 저전력 DSP 코어 설계와 노이즈 및 에코 제거 알고리즘을 적극 활용하여 구현하였다”며 “WhisPro는 엣지 디바이스 및 클라우드 기반 음성인식 비서 기능 서비스를 지원하며 고객이 그들의 디바이스를 전유의 문구로 제어할 수 있도록 하는 고유한 트리거 프레이즈(Trigger Phrase, 작동 문구)를 사용할 수 있도록 지원한다”고 말했다.
이향선기자 hslee@nextdaily.co.kr